Учебное пособие -> Глава 4. Организация
компьютерных систем: процессоры
Глава 4. Организация компьютерных систем:
процессоры
Центральный процессор — это мозг компьютера.
Рисунок 1 -
Примеры центральных процессорв
Его задача — выполнять программы, находящиеся в основной
памяти. Он вызывает команды из памяти, определяет их тип, а затем выполняет одну
за другой.
Компоненты соединены шиной, представляющей собой набор
параллельно связанных проводов, по которым передаются адреса, данные и сигналы
управления. Шины могут быть внешними ((связывающими процессор с памятью и
устройствами ввода-вывода) и внутренними.
Рисунок 2 - Схема компьютера с одним
центральным процессором
и двумя устройствами ввода-вывода
Общие принципы построения микропроцессоров
Сколь бы сложным ни был микропроцессор, в составе его
всегда можно выделить следующие
основные блоки или устройства, такие какоперационный и управляющий
блоки.
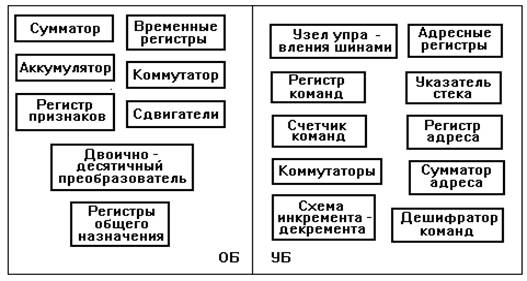
Рисунок 3 -Общая логическая структура МП
Операционный блок (ОБ)предназначен для арифметической и логической обработки информации. Он
обычно включает в себя следующие основные узлы: двоичный сумматор, аккумулятор,
регистры общего назначения, временные регистры, регистр признаков, сдвигатели,
двоично - десятичный преобразователь, коммутатор.
Двоичный сумматор параллельного типа имеет число
разрядов, равное числу разрядов шины данныхмикропроцессора. В простейших схемах МП перенос между разрядами сумматора
осуществляется последовательно, в более сложных схемах используется параллельно
- последовательный либо параллельно - параллельный принцип организации
переносов.
На раннем этапе развития микропроцессорной техники, когда
степень интеграции на кристаллах была невысокой, использовался, как правило,
последовательный перенос между разрядами сумматора. При этом обеспечивалась
простейшая схемотехническая реализация, правда, за счет некоторого снижения
быстродействия. В настоящее время используется либо параллельно -
последовательная организация переносов, когда внутри разрядов переносы
формируются одновременно, а передача переносов между группами производится
последовательно, либо параллельно - параллельная организация, когда формирование
переносов внутри групп разрядов, а также по принципу одновременного переноса,
когда перенос информации осуществляетсямежду группами разрядов. При этом, естественно усложняется
схемотехническая реализация, но благодаря этому достигается более высокое
быстродействие сумматора.
Аккумулятор (или регистр - накопитель) имеет число
разрядов, равное числу разрядов сумматора. В командах МП, выполнение которых
непосредственно связано с использованием аккумулятора, он служит для хранения
одного из двух операндов, над которыми производится данная арифметическая или
логическая операция, в него такжезаносится результат выполненной операции. Кроме того, через аккумулятор,
как правило, производится обмен данными МП с УВВ, если не задействованы другие
способы обмена, например, способ прямого доступа к памяти.
Регистры общего назначения (РОН), имеющиеся в
большинстве МП, обычно относит к устройству обработки данных. Они используются в
МП либо для хранения данных, полученных в процессе вычислений, либо в качестве
адресных регистров для формирования адреса внешнего устройства или ячейки памяти
искомого операнда или команды, либо в качестве регистров специального
назначения. Чаще всего РОН
используются в качестве СОЗУ, т.е. относительно небольшой области памяти,
расположенной непосредственно на самом кристалле МП. Обращение к СОЗУ происходит
намного быстрее, чем к обычному ОЗУ, благодаря упрощенной адресации и очень
малым задержкам передачи информации. Поэтому использование их в качестве
сверхоперативной памяти позволяет существенно повысить производительность
микропроцессора.
При использовании РОН в качестве регистров хранения данных
они адресуются по отдельности, то есть используются как самостоятельные
регистры. При использованиив
качествеадресных регистров они
адресуются попарно, то есть их загрузка осуществляется попарно.
РОН в ряде МП могут выполнять функции специальных регистров
- сброс, инкремент, декремент и т. д.
Временные регистры имеют разрядность, равную
разрядности ШД МП. Они предназначены для временного хранения данных при
пересылках их между различными узлами микропроцессора. Необходимость
использования регистров временного хранения данных вытекает из того, чтопередача данных в синхронных системах, каковыми является подавляющее
большинство МП, осуществляется за два этапа:первый этап -передача
информации, второй этап - прием информации (или наоборот). Узлы, участвующие в
обмене данными, не могут одновременно передавать и принимать информацию. А
поскольку подавляющее большинство регистров в МП построено на одноступенчатых
триггерах, позволяющих реализацию одного этапа передачи данных, товозникает необходимость иметь в МП некоторые вспомогательные регистры,
которыепозволяли бы реализоватьвторой этап передачи данных. Эту функцию выполняют временные регистры.
Регистр признаков (регистр состояний). ВМП регистр признаков представляет собой совокупность триггеров - флажков,
каждый из которых отражает
результат очередной операции, выполненной в арифметико-логическом устройстве
(АЛУ). Поскольку триггеры - флажки отражают результат операций АЛУ,
топологически регистр признаков размещается вблизи него.
В большинстве МПпринят следующий набор признаков и соответственно триггеров - флажков:
ѕ
перенос(триггер - флажок
устанавливается в состояние логической «1» при наличии переноса из старшего
разряда или при наличии займа в старший разряд),
ѕ
отрицательный результат
(флажок устанавливается в «1» при отрицательном результате операции),
ѕ
нулевой результат(флажок
устанавливается в «1» при нулевом результате операции),
ѕ
переполнение(флажок
устанавливается в «1» при переполнении, когда результат операции над числами со
знаком выходит за пределы диапазона представляемых чисел).
В различных МП используется свой набор триггеров - флажков,
который может и чаще всего отличается от приведенного выше стандартного набора.
Таким образом, триггеры - флажки отражают информацию о
признаках результата очередной выполненнойАЛУ операции. Эти признаки результата, в более общем случае - признаки
состояния, используютсяв качестве
сигналов управления ходом выполнения программы. По значениям признаков, которые
периодически считываются МП, в частности, выполняются условные переходы при
ветвлениях программы, при переходе на подпрограммы и т.д.
В более поздних разработках МП в регистр признаков помимотриггеров - флажков результата выполненной операций включены и некоторые
другие триггеры,способные отражать
состояние МП на различных участках выполняемой программы, например, разрешение
прерываний, вид адресации, режим пользования, режим трассировки (режим
прерывания после выполнения каждой операции), состояние стека, десятичная
коррекция и др. При этом в каждом конкретном МП используется свой определенный
набор дополнительных признаков состояния.
Сдвигатели имеют число разрядов, равное числу
разрядов сумматора. Они используются для выполнения циклических, арифметических
или логических сдвигов, которые могут осуществляться либо влево (в сторону
старших разрядов),либо вправо (в
сторону младших разрядов). Сдвиги в одних МП могут производиться наодин разряд, в других - на произвольное число разрядов вплоть дo полного
числа разрядов данного микропроцессора.
Сдвигатели используются, прежде всего, при выполнении
операций вычитания и деления.
Двоично - десятичный преобразователь или схема
десятичной коррекции позволяет произвести преобразование двоичного кода числа,
находящегося в аккумуляторе, в двоично - десятичный код. Он используется в тех
случаях, когда полученную информацию необходимо вывести в десятичной системе
счисления, например, на индикацию. Вывод осуществляется по специальной команде.
В этом случае отпадает необходимость в использовании дополнительных схем
декодирования кода в формат, воспринимаемыйблоком индикации.
Коммутаторы (мультиплексоры и демультиплексоры)
имеют разрядность, равную разрядности АЛУ. Мультиплексоры позволяют передавать в
АЛУ числа (операнды) от различных источников в различной комбинации пар
операндов. Демультиплексоры позволяют направить информацию с АЛУ на различные
приемники информации.
Управляющий блок (УБ) является важнейшим функциональным
узлом блока интерфейса, обеспечивающим взаимодействие МП с ОЗУ и УВВ. Он
включает в себя: регистр команд (в ряде МП вместонего используется регистр очереди команд), дешифратор команд, счетчик
команд, указатель стека, схему инкремента/декремента, сумматор адреса, регистр
адреса (регистр - защелка адреса), коммутаторы, узел управления шинами, а также
вспомогательные регистры.
Регистр команд используется в тех МП, где выбранные
из программной памяти команды сразу же вводятся в МП на исполнение. Он
предназначен для приема и хранения кода операции (КОП) команд на время их
выполнения МП.
Регистр очереди команд используется в тех МП, где выбранные из
программной памяти команды помещаютсяв очередь команд, выполняемых МП. Заполнение регистра производится в
интервалы времени, когда ШД МП не занята им для обмена данными с основной
памятью (ОП) или ВУ. Выборка команд из очереди команд производится МП по мере их
выполнения. Таким образом, обеспечивается повышение производительности МП,
поскольку каждый раз после выполнения очередной командыне требуется дополнительных затрат времени на выборку следующей команды
из ПЗУ, очередные команды уже находятся в буферной памяти МП.
Полное время на выборку команды с обращением к ПЗУ тратится
лишь в тех случаях, когда производится передача управления при реализации
условных переходов в программе. В этих случаях производится реинициализация, то
есть сброс, очереди команд и загрузка ее новой последовательностью команд. При
этом первая же выбранная из ПЗУ команда становится сразу доступной для
выполнения.
Одной из разновидностей реализации очереди команд являетсякэш - память, размещаемая непосредственно на кристалле МП и являющаяся
самой быстродействующей памятью системы. В ряде МП кэш - память используетсякак буферное ЗУне только
для потока команд, но также и для потока данных. Емкость такого буферного
запоминающего устройства достигает 256 байт и более.
Дешифратор команд является обязательным узлом
управляющего блока МП. С помощью дешифратора команд декодируется содержимое КОП.
В результате декодирования команды МП определяет вид операции, предписанной к
выполнению МП данной командой, число байт в команде, время выполнения команды и
т. д. Эти параметры необходимы управляющему блокудляформирования
соответствующих управляющих сигналов, обеспечивающих взаимодействие всех узлов
МП и устройств МПС.
Счетчик команд (программный счетчик, указатель
инструкций) предназначен для формирования адреса следующей выбираемой из ПЗУ
команды. Он представляет собой
регистр иотноситсяк регистрам специального назначения, т. к. в отличие от РОН выполняет
только свои определенные функции - инкремент, сброс в любое промежуточное или
исходное (нулевое) состояние и т. д.
Формирование адреса в счетчике команд осуществляется
инкрементированием (приращением) определенного числа (1, 2, 4) кего содержимому. Инкрементирование осуществляется каждый раз, когда
формируется либо адрес кода операции следующей команды, либо адрес числа,
представляющего собой адресную часть команды, либо адрес непосредственных
данных, содержащихся в команде. Операция инкрементирования содержимого счетчика
команд производится автоматически при пересылках адреса.
Возможны два вариантаформирования адреса очередной команды в счетчикекоманд:
ѕ
последовательной выборкой - путем добавления «1», «2», «4» к содержимому
счетчика команд;
ѕ
обновлением содержимого счетчика команд - путем загрузки в счетчик нового числа,
представляющего собой новый адрес при реализации переходов в программе.
В 32 - разрядных однокристальных МП счетчик команд имеет 32
разряда, что позволяет разместить программу в любой области адресного
пространства размером до 4 Гбайт.
Указатель стека. Стек представляет собой область ОЗУ
с последовательной организацией доступа к ячейкам памяти по принципу "первым
пришел - последним ушел». В отличие от ЗУ с произвольной выборкой, в котором при
каждом обращении доступна ячейка памяти с любым адресом, в стеке доступной
является только одна ячейка памяти в последовательном списке адресов: либо
последняя занятая - при считывании, либо первая свободная - при записи. Таким
образом, при обращениях к стеку происходит последовательный перебор адресов. В
МП при обращениях к стеку принят следующий порядок адресации: при записи в стек
- номера ячеек памяти убывают, а при считывании – возрастают. Другими словами,
стек заполняется в направлении уменьшения адресов.
Ячейка памяти, выше которой располагается первая ячейка
стека, называется дном стека, а последняяиз заполненных ячеек памяти называют вершинойили головкой стека. Адресация к ячейкам памяти стека осуществляется с
помощью указателя стека (SP
- Stake Point).
Схема инкремента/декремента является узлом, который
осуществляетоперацию добавления
«1», «2», «4» к содержимому счетчика команд либо добавления/уменьшения «1», «2»,
«4» к содержимому указателя стека. Этот процесс происходит при передаче
информации по цепочке: счетчик команд (указатель стека) ®
регистр - защелка адреса ®
схема инкремента/декремента ®
счетчик команд (указатель стека).
Схема инкремента/декремента при реализации различных
способов адресации может использоваться для манипуляций с содержимым не только
счетчика и указателя стека, но и других адресных регистров.
Сумматор адреса является вспомогательным узлом и
используется для вычисления адреса при применении сложных методов адресации
(индексная, базовая) для того, чтобы не занимать этими вычислениями основной
сумматор АЛУ. Вспомогательный сумматор адреса должен прибавлять базовый адрес к
содержимому индексного регистра (при индексной адресации) либо прибавлять
смещение к содержимому базового регистра (при базовойадресации), а так же осуществлять аналогичные операции при использованиидругих сложных методов адресации.
Адресные регистры используются для формирования и
хранения операндов или адресов пересылки результата операции. Они необходимы, в
частности, для реализации различных комбинированных (многокомпонентных) способов
адресации.
Регистр адреса (регистр - защелка адреса) предназначен для
хранения адреса при обращениях к памяти на время данного цикла обращения. Само
формирование адреса до передачи его в регистр - защелку производится в других
узлах МП: в счетчике команд, в
указателе стека, адресных регистрах.
Регистр - защелка адреса имеет разрядность, равную
разрядности ШД МП.
Вспомогательные регистры и схемы коммутации. В узле
формирования адресов памяти и в блоке интерфейса в целом, так же как и в
устройстве обработки данных, имеется один или несколько вспомогательных
регистров -регистров обмена, через
которые осуществляется передача информации как внутри самого блока интерфейса,
так и между блоком интерфейса и другими устройствами МП. В блоке интерфейса
имеется также определенное количество коммутаторов - мультиплексоров и
демультиплексоров. Через них осуществляется выборка тех или иных регистров, в
которых хранятся компоненты адресов, а также реализуются все пересылки внутри
блока интерфейса и все его связи с другими блоками МП и с ВУ.
Узел управления шинами осуществляет управление
работой всех шин, а именно: переключением направления передачи данных,
переключением мультиплексированных шин на передачу данных, адреса или сигналов
управления, отключением шин от системной магистрали путем переводавыходных каскадов в третье состояние и др. Он представляет собой буферную
схему - совокупность логических ключей (вентилей), работающих под воздействием
сигналов управления МП.
Буферные схемы осуществляют выполнение следующих
функций:
ѕ
обеспечивают необходимую загрузочную способность выходов МП по активному току
нагрузкиIни по паразитной нагрузки Сн ;
ѕ
согласовывают внутренние логические уровни сигналов с внешними стандартными
уровнями.
Практически все выходные буферные каскады МП имеют три
состояния: первое состояние - логический «0», второе состояние -логическая «1», третье состояние - высокоимпедансное или отключенное
состояние каскада. Перевод выходных каскадов МП в одно из перечисленных
состояний осуществляется путем подачи на буферные схемы соответствующихсигналов управления. Это позволяет двунаправленную передачу данных в
системе либо отключение МП от общей магистрали МПС.
Типы процессоров. RISC, CISC И MISC
Одним из важнейших компонентов ЭВМ является процессор.
Двумя основными архитектурами процессоров, используемыми компьютерной
промышленностью на современном этапе развития вычислительной техники, являются
архитектуры CISC и RISC.
CISC(ComplexInstructionSetComputing -
вычисления с полным набором команд) - архитектура процессоров, характеризующаяся
следующими свойствами:
-нефиксированное значение длины команды;
-исполнение операций кодируется в одной
инструкции;
-небольшое число регистров, каждый из которых
выполняет строго определенную функцию;
-- большое количество методов адресации;
-- большое количество машинных команд, некоторые
из которых нагружены семантически аналогично операторам высокоуровневых языков
программирования и выполняются за много тактов;
-- большое количество форматов команд различной
разрядности.
Основоположником CISC-архитектуры можно считать компанию
IBM с базовой архитектурой System/360. Лидером в разработке микропроцессоров c
полным набором команд считается компания Intel с серией x86 и Pentium. Эта
архитектура является практическим стандартом для рынка микрокомпьютеров.
RISC (Reduced Instruction Set Computing - вычисления с
сокращенным набором команд) - архитектура процессоров, характеризующаяся
следующими свойствами:
-фиксированная длина машинных инструкций и простой
формат команды;
-одна инструкция выполняет только одну операцию с
памятью - чтение или запись;
-большое количество регистров общего назначения
(32 и более).
Идея создания RISC процессоров появилась после того, как в
1970-х годах ученые из IBM обнаружили, что многие из функциональных особенностей
традиционных процессоров игнорировались программистами. Отчасти это был побочный
эффект сложности компиляторов. Поэтому многие ранние RISC-процессоры даже не
имели команд умножения и деления. В то время компиляторы могли использовать лишь
часть из набора команд процессора. Развитие архитектуры RISC в значительной
степени определялось прогрессом в области создания оптимизирующих компиляторов.
Развитие техники компиляции позволяет эффективно использовать преимущества
большего регистрового файла, конвейерной организации и большей скорости
выполнения команд. Поскольку некоторые сложные операции использовались редко,
они, как правило, были медленнее, чем те же действия, выполняемые набором
простых команд. Это происходило из-за того, что создатели процессоров тратили
гораздо меньше времени на улучшение сложных команд, чем на улучшение простых.
Современные компиляторы используют преимущества другой
оптимизационной техники для повышения производительности, обычно применяемой в
процессорах RISC - реализацию задержанных переходов и суперскалярной обработки,
позволяющей в один и тот же момент времени выдавать на выполнение несколько
команд.
Недостатки RISC архитектуры:
-RISC команды более медленны, для их выполнения
используется многоступенчатый конвейер, однако всякий раз при ветвлении
программы конвейер сбрасывается и заполняется заново;
-с увеличением быстродействия растет разрыв между
быстрым процессором и медленной памятью, для увеличения скорости доступа к
памяти необходимо использовать кэш память для буферизации потоков данных и
команд, однако кэш память усложняет и удорожает систему в целом;
-RISC процессоры неэффективны на операциях вызова
и возврата подпрограмм. Эффективность этого механизма критична для языков
высокого уровня. Многие RISC процессоры используют большой регистровый файл с
окнами для облегчения вызова подпрограмм. Однако, окно должно быть достаточно
большое для сохранения локальных данных. Большой регистровый файл – это потеря
наиболее драгоценных ресурсов процессора и замедление при переключении контекста
на его сохранение и восстановление.
Тем не менее, современные процессоры Intel и AMD являются
CISC-процессорами с RISC-ядром. Они непосредственно перед исполнением
преобразуют CISC-инструкции процессоров x86 в более простой набор внутренних
инструкций RISC. В микропроцессор встраивается аппаратный транслятор,
превращающий команды x86 в команды внутреннего RISC-процессора. При этом одна
команда x86 может порождать несколько RISC-команд. Исполнение команд происходит
параллельно на суперскалярном конвейере. Это потребовалось для увеличения
скорости обработки CISC-команд, так как известно, что любой CISC-процессор
уступает RISC-процессорам по количеству выполняемых операций в секунду. В итоге,
такой подход и позволил поднять производительность процессоров x86.
MISC(англ. MinimalInstructionSetComputerминимальный набор команд) - архитектура процессоров, характеризующаяся
следующими свойствами:
-небольшое число чаще всего встречающихся команд;
-принципVLIW(Verylonginstructionword - очень
длинное командное слово) - укладка нескольких команд в одно большое слово,
позволяет обрабатывать одновременно несколько потоков данных, обеспечивает
выполнение группы непротиворечивых команд за один цикл работы процессора;
-порядок выполнения команд распределяется таким
образом, чтобы в максимальной степени загрузить маршруты, по которым проходят
потоки данных.
По мнению авторов концепции архитектуры MISC сокращение
набора команд является эффективным шагом по повышению производительности. Был
исследован вопрос достижения высокой производительности с ограничением на
максимальную простоту с целью определения насколько современная технология
производства транзисторов может уменьшить стоимость построения компьютера.
Авторы MISC процессора пришли к выводу, что число команд должно быть в районе
32-х, для них используется 5-и разрядное поле команды, в каждое 20-и разрядное
слово помещается четыре команды, а в каждое 32-х разрядное слово может
поместиться шесть команд с запасом. Система команд MISC достаточно проста и
помещается на одной странице. Сокращение набора команд является эффективным
шагом по повышению производительности.
Матричный процессоробъединяет множество функциональных устройств, логически объединенных в
матрицу и работающих в стиле один поток команд - множество потоков данных.
Данный процессор лучше всего приспособлен для решения задач, характеризующихся
параллелизмом независимых объектов или данных. Структура матричного процессора
состоит из общего управляющего устройства, генерирующего поток команд и большого
числа процессорных элементов, работающих параллельно и обрабатывающих каждая
свой поток данных. Таким образом, производительность системы оказывается равной
сумме производительностей всех процессорных элементов. На практике, чтобы
обеспечить достаточную эффективность системы при решении широкого круга задач
необходимо организовать связи между процессорными элементами с тем, чтобы
наиболее полно загрузить их работой.
Векторный процессор- это процессор, в котором операндами некоторых команд могут выступать
упорядоченные массивы данных- векторы. Отличается от обычных процессоров,
которые могут работать только с одним операндом в единицу времени. Векторные
процессоры были распространены в сфере научных вычислений, где являлись основой
большинства суперкомпьютеров с 1980-х до 1990-х.
Принципы разработки современных компьютеров
Прошло более двадцати лет с тех пор, как были
сконструированы первые компьютеры RISC, однако некоторые принципы их
функционирования можно перенять, учитывая современное состояние технологии
разработки аппаратного обеспечения. Если происходит очень резкое изменение в
технологии, томеняются все
условия. Поэтому разработчики всегда должны учитывать возможные технологические
изменения, которые могли бы повлиять на баланс между компонентами компьютера.
Существует ряд принципов разработки, которым по возможности
стараются следовать производители универсальных процессоров. Из-за некоторых
внешних ограничений, например требования совместимости с другими машинами,
приходится время от времени идти на компромисс, но эти принципы — цель, к
которой стремятся большинство разработчиков.
-Все команды должны выполняться непосредственно
аппаратным обеспечением. То есть обычные команды не интерпретируются
микрокомандами. Устранение уровня интерпретации повышает скорость выполнения
большинства команд. В компьютерах типа CISC более сложные команды могут
разбиваться на несколько шагов, которые затем выполняются как последовательность
микрокоманд. Эта дополнительная операция снижает быстродействие машины, но может
использоваться для редко применяемых команд.
-Компьютер должен запускать как можно больше
команд в секунду. В современных компьютерах используется много различных
способов повышения производительности, главный из которых — запуск как можно
большего количества команд в секунду. Процессор 500-MIPS способен запускать 500
млн команд в секунду, и при этом не имеет значения, сколько времени занимает
выполнение этих команд. (MIPS — это сокращение от
MillionsofInstructionsPerSecond —
миллионы команд в секунду.) Этот принцип предполагает, что параллелизм должен
играть главную роль в повышении производительности, поскольку запустить на
выполнение большое количество команд за короткий промежуток времени можно только
в том случае, если есть возможность одновременного выполнения нескольких команд.
-Команды должны легко декодироваться. Предел
количества запускаемых в секунду команд зависит от темпа декодирования отдельных
команд. Декодирование команд позволяет определить, какие ресурсы им необходимы и
какие действия нужно выполнить. Полезно все, что способствует упрощению этого
процесса. Например, можно использовать единообразные команды с фиксированной
длиной и с небольшим количеством полей. Чем меньше разных форматов команд, тем
лучше.
-К памяти должны обращаться только команды
загрузки и сохранения. Один из самых простых способов разбить операцию на
отдельные шаги — сделать так, чтобы операнды большей части команд брались из
регистров и возвращались туда же. Операция перемещения операндов из памяти в
регистры и обратно может осуществляться в разных командах. Поскольку доступ к
памяти занимает много времени, причем длительность задержки не поддается
прогнозированию, выполнение этих команд могут взять на себя другие команды,
единственное назначение которых — перемещение операндов между регистрами и
памятью. То есть к памяти должны обращаться только команды загрузки и
сохранения.
-Регистров должно быть много. Поскольку доступ к
памяти происходит довольно медленно, в компьютере должно быть много регистров.
Если слово однажды вызвано из памяти, при наличии большого числа регистров оно
может содержаться в регистре до тех пор, пока не потребуется. Возвращение слова
из регистра в память и новая загрузка этого же слова в регистр нежелательны.
Лучший способ избежать излишних перемещений — наличие достаточного количества
регистров.
Системы команд процессора
В команде процессора четко выделяют две частиоперационная и адресная. Формат командыэто описание размеров и взаимного расположения структурных частей
команды. Всегда стараются сделать так, чтобы команда занимала целое число
элементов хранения.
У разных процессоров системы команд существенно
различаются, но в основе своей они очень похожи. Количество команд у процессоров
также различно. У современных мощных процессоров количество команд достигает
нескольких сотен. В то же время в процессорах с сокращенным набором команд
(RISC-процессорах), в которых за счет максимального сокращения количества команд
достигается увеличение эффективности и скорости их выполнения, их количество
невелико.
В общем случае система команд процессора включает в себя
следующие основные группы команд:
-команды пересылки данных;
-арифметические команды;
-логические команды;
-команды переходов;
-специальные команды.
Команды пересылки данных.
Команды пересылки данных не требуют выполнения никаких операций над
операндами. Операнды просто пересылаются из источника в приемник. Источником и
приемником могут быть внутренние регистры процессора, ячейки памяти или
устройства ввода/вывода. АЛУ в данном случае не используется.
Команды пересылки выполняют следующие важнейшие функции:
-загрузка (запись) содержимого во внутренние
регистры процессора;
-сохранение в памяти содержимого внутренних
регистров процессора;
-копирование содержимого из одной области памяти в
другую;
-запись в устройства ввода/вывода и чтение из
устройств ввода/вывода.
Также к командам пересылки данных относятся команды обмена
информацией. Может быть предусмотрен обмен информацией между внутренними
регистрами, между двумя половинами одного регистра или между регистром и ячейкой
памяти.
Арифметические
команды
Арифметические команды выполняют операции сложения,
вычитания, умножения, деления, увеличения на единицу (INC-инкремент), уменьшения
на единицу (DEC-декремент) и т.д. Этим командам требуется один или два входных
операнда. Формируют команды один выходной операнд.
Арифметические команды могут быть разделены на несколько
основных групп:
-команды операций с фиксированной запятой
(сложение, вычитание, умножение, деление);
-команды операций с плавающей запятой (сложение,
вычитание, умножение, деление);
-команды очистки;
-команды INC и DEC;
-команда сравнения.
Команды операций с фиксированной запятой работают с кодами
в регистрах процессора или в памяти как с обычными двоичными кодами, причем все
эти команды могут работать как с числами со знаком, так и с числами без знака.
Команды операций с плавающей запятой (точкой) используют
формат представления чисел с порядком и мантиссой. В современных мощных
процессорах набор команд с плавающей запятой не ограничивается только четырьмя
арифметическими действиями, а содержит и множество других более сложных команд,
например, вычисление тригонометрических функций, логарифмических функций, а
также сложных функций, необходимых при обработке звука и изображения.
Команды очистки предназначены для записи нулевого кода в
регистр или ячейку памяти. Эти команды могут быть заменены командами пересылки
нулевого кода, но специальные команды очистки обычно выполняются быстрее, чем
команды пересылки. Команды очистки иногда относят к группе логических команд, но
суть их от этого не меняется.
Команды инкремента и декремента также бывают очень удобны.
Их можно заменить командами суммирования с единицей или вычитания единицы, но
инкремент и декремент выполняются быстрее, чем суммирование и вычитание. Эти
команды требуют одного входного операнда, который одновременно является и
выходным операндом.
Команда сравнения предназначена для сравнения двух входных
операндов. По сути, она вычисляет разность этих двух операндов, но выходного
операнда не формирует, а всего лишь изменяет биты в регистре состояния
процессора по результату этого вычитания. Следующая за командой сравнения
команда (обычно это команда перехода) анализирует биты в регистре состояния
процессора и выполняет действия в зависимости от их значений.
Логические команды
Логические команды выполняют над операндами логические
(побитовые) операции, то есть они рассматривают коды операндов не как единое
число, а как набор отдельных битов.
Логические команды выполняют следующие основные операции:
-логическое И, логическое ИЛИ, сложение по модулю
2 (исключающее ИЛИ);
-логические, арифметические и циклические сдвиги;
-проверка битов и операндов;
-установка и очистка битов (флагов) регистра
состояния процессора.
Команды логических операций позволяют побитно вычислять
основные логические функции от двух входных операндов. Команды требуют двух
входных операндов и формируют один выходной операнд. Команды сдвига позволяют
побитно сдвигать код операнда вправо (в сторону младших разрядов) или влево (в
сторону старших разрядов). Тип сдвига (логический, арифметический или
циклический) определяет, каково будет новое значение старшего бита (при сдвиге
вправо) или младшего бита (при сдвиге влево), а также определяет, будет ли
где-то сохранено прежнее значение старшего бита (при сдвиге влево) или младшего
бита (при сдвиге вправо).
Команды проверки битов и операндов предназначены для
установки или очистки битов регистра состояния процессора в зависимости от
значения выбранных битов или всего операнда в целом. Выходного операнда команды
не формируют. Команда проверки операнда проверяет весь код операнда в целом на
равенство нулю и на знак (на значение старшего бита), она требует только одного
входного операнда.
Команда проверки бита проверяет только отдельные биты, для
выбора которых в качестве второго операнда используется код маски. В коде маски
проверяемым битам основного операнда должны соответствовать единичные разряды.
Команды перехода
Команды перехода предназначены для изменения обычного
порядка последовательного выполнения команд. С их помощью организуются переходы
на подпрограммы и возвраты из них, всевозможные циклы, ветвления программ,
пропуски фрагментов программ и т.д. Команды перехода всегда меняют содержимое
счетчика команд. Переходы могут быть условными и безусловными.
Некоторые команды перехода предусматривают в дальнейшем
возврат назад, в точку, из которой был сделан переход, другие не предусматривают
этого. Если возврат предусмотрен, то текущие параметры процессора сохраняются в
стеке. Если возврат не предусмотрен, то текущие параметры процессора не
сохраняются.
Команды перехода с дальнейшим возвратом в точку, из которой
был произведен переход, применяются для выполнения подпрограмм, то есть
вспомогательных программ. Эти команды называются также командами вызова
подпрограмм. Использование подпрограмм позволяет упростить структуру основной
программы, сделать ее более логичной, гибкой, легкой для написания и отладки. В
то же время надо учитывать, что широкое использование подпрограмм, как правило,
увеличивает время выполнения программы.
Команды перехода позволяют строить сложные алгоритмы
обработки информации.
Особое место среди команд перехода с возвратом занимают
команды прерываний (Interrupt, INT). Эти команды в качестве входного операнда
требуют номер прерывания.
У конкретных процессоров могут быть и многие другие
(специальные) команды, не относящиеся к перечисленным группам команд.
Существует несколько принципов управления потоком команд:
-последовательное выполнение команд
(фон-Неймановская архитектура);
-по мере готовности данных (параллельная
архитектура);
-по мере потребности в результатах выполнения
(редукционно-программное управление).
Основные видыадресации: прямая, косвенная, относительная. Использование сложных
методов адресации позволяет существенно сократить количество команд в программе,
но при этом значительно увеличивается сложность аппаратуры.
Современные способы повышения производительности процессоров
Разработчики компьютеров стремятся к тому, чтобы повысить
производительность своих машин. Один из способов заставить процессоры работать
быстрее — повышение их тактовой частоты, однако при этом существуют некоторые
технологические ограничения, связанные с конкретным историческим периодом.
Поэтому большинство разработчиков для повышения производительности при данной
тактовой частоте процессора используют параллелизм (выполнение двух или более
операций одновременно).
Существует две основные формы параллелизма:
1.параллелизм на уровне команд;
2.параллелизм на уровне процессоров.
В первом случае параллелизм реализуется за счет запуска
большого количества команд каждую секунду.
Во втором случае над одним заданием работают одновременно
несколько процессоров.
Каждый подход имеет свои преимущества.
Главным препятствием высокой скорости выполнения команд
является необходимость их вызова из памяти. Разработчики архитектуры компьютеров
стараются применять методы проектирования, известные под общим названием
совмещение операций, при котором аппаратура компьютера в любой момент времени
выполняет одновременно более одной базовой операции. Эти общие методы включают
два различных подхода: параллелизм и конвейеризацию.
Конвейерная
обработкаоснована на разделении подлежащей исполнению функции на более мелкие
части, называемые ступенями, и выделении для каждой из них отдельного блока
аппаратуры. При этом обработка любой машинной команды разделяется на несколько
этапов, организуется передача данных от одного этапа к следующему.
Производительность при этом возрастает благодаря тому, что
одновременно на различных ступенях конвейера выполняются несколько команд.
Конвейерная обработка такого рода широко применяется во всех современных
быстродействующих процессорах. Конвейерная обработка эффективна только при
загрузке конвейера близкой к полной.
На рисунке изображен конвейер из пяти блоков, которые
называются ступенями.
-Первая ступень (блок С1) вызывает команду из
памяти и помещает ее в буфер, где она хранится до тех пор, пока не потребуется.
-Вторая ступень (блок С2) декодирует эту команду,
определяя ее тип и тип ее операндов.
-Третья ступень (блок СЗ) определяет
местонахождение операндов и вызывает их из регистров или из памяти.
-Четвертая ступень
(блок С4) выполняет команду, обычно проводя операнды через тракт данных.
-Блок С5
записывает результат обратно в нужный регистр.
1.Во время цикла 1 блок С1 обрабатывает команду 1, вызывая
ее из памяти.
2.Во время цикла 2 блок С2 декодирует команду 1, в то
время как блок С1 вызывает из памяти команду 2.
3.Во время цикла 3 блок СЗ вызывает операнды для команды
1, блок С2 декодирует команду 2, а блок С1 вызывает команду 3.
4.Во время цикла 4 блок С4 выполняет команду 1, СЗ
вызывает операнды для команды 2, С2 декодирует команду 3, а С1 вызывает команду
4.
5.Во время цикла 5 блок С5 записывает результат выполнения
команды 1 обратно в регистр, тогда как другие ступени конвейера обрабатывают
следующие команды.
Конвейеры позволяют
добиться компромисса между временем запаздывания (время выполнения одной
команды) и пропускной способностью процессора (количество команд, выполняемых
процессором в секунду). Если время обращения составляет Т нс, а конвейер имеет
n
ступеней, время запаздывания составит nTнс.
Суперскалярные архитектуры
Одна из возможных схем
процессора с двумя конвейерами показана на рисунке.
Здесь общий блок выборки
команд вызывает из памяти сразу по две команды и помещает каждую из них в один
из конвейеров. Каждый конвейер содержит АЛУ для параллельных операций. Чтобы
выполняться параллельно, две команды не должны конфликтовать из-за ресурсов
(например, регистров), и ни одна из них не должна зависеть от результата
выполнения другой.
Как и в случае с одним
конвейером, либо компилятор должен гарантировать отсутствие нештатных ситуаций
(когда, например, аппаратура не обеспечивает проверку команд на несовместимость
и при обработке таких команд выдает некорректный результат), либо за счет
дополнительной аппаратуры конфликты должны выявляться и устраняться
непосредственно в ходе выполнения команд.
Сначала конвейеры (как сдвоенные, так и обычные)
использовались только в RISC-компьютерах. У процессора 386 и его
предшественников их не было. Конвейеры в процессорах компании Intel появились,
только начиная с модели 486. Процессор 486 имел один пятиступенчатый конвейер, a
Pentium — два таких конвейера. Главный конвейер (u-конвейер) мог выполнять
произвольные команды. Второй конвейер (v-конвейер) мог выполнять только простые
команды с целыми числами, а также одну простую команду с плавающей точкой.
Имеются сложные правила определения, является ли пара команд совместимой в
отношении возможности параллельного выполнения. Если команды, входящие в пару,
были сложными или несовместимыми, выполнялась только одна из них (в
u-конвейере). Оставшаяся вторая команда составляла затем пару со следующей
командой. Команды всегда выполнялись по порядку.
Таким образом, процессор Pentium содержал особые
компиляторы, которые объединяли совместимые команды в пары и могли порождать
программы, выполняющиеся быстрее, чем в предыдущих версиях. Измерения показали,
что программы, в которых применяются операции с целыми числами, при той же
тактовой частоте на Pentium выполняются почти в два раза быстрее, чем на 486.
Переход к четырем конвейерам возможен, но требует
громоздкого аппаратного. Вместо этого используется другой подход, основная идея
которого — один конвейер с большим количеством функциональных блоков.
Со временем значение понятия «суперскалярный» несколько
изменилось. Теперь суперскалярными называют процессоры, способные запускать
несколько команд (зачастую от четырех до шести) за один тактовый цикл.
Естественно, чтобы передавать все эти команды, в суперскалярном процессоре
должно быть несколько функциональных блоков.