Учебное пособие -> Глава 11. Многопроцессорные
вычислительные системы
Глава 11. Многопроцессорные вычислительные системы
Наиболее перспективным и динамично развивающимся
направлением увеличения производительности вычислительных систем, а
соответственно и скорости решения прикладных задач, является применение идей
параллелизма к работе вычислительных систем. К настоящему времени спроектированы
и опробованы сотни различных компьютеров, использующих в своей архитектуре тот
или иной вид параллельной обработки данных.
Основные проблемы:
-Главная проблема -скорость света - невозможно заставить протоны и электроны двигаться
быстрее.
-Из-за высокой теплоотдачи компьютеры превратились
в кондиционеры.
Поскольку размеры транзисторов постоянно уменьшаются
основной проблемой могут стать законы квантовой механики. В результате, чтобы
иметь возможность решать более сложные задачи, разработчики обратились к
компьютерам параллельного действия.
Уровни параллелизма
-На самом низком уровне параллелизм может быть
реализован в процессоре за счет конвейеризации и суперскалярной архитектуры с
несколькими функциональными блоками. Еще одним вариантом является с крытый
параллелизм - значительное удлинение слов в командах. Также можно «научить»
процессор одновременно обрабатывать несколько программных потоков. Все это дает
повышение производительности максимум в 10 раз.
-На следующем уровне возможно внедрение в систему
внешних плат ЦП с улучшенными вычислительными возможностями. В подключаемых
процессорах реализуются специальные функции, такие как обработка сетевых
пакетов, обработка мультимедийных данных, криптография и т.д. Производительность
специализированных приложений может быть повышена в 5-10 раз.
-Для повышения производительности в очень-очень
много раз необходимо свести воедино многочисленные процессоры и обеспечить их
эффективное взаимодействие. Реализация - мультипроцессорные системы и
мультикомпьютеры.
-В последнее время появилась возможность
интеграции через Интернет целых организаций. В результате формируются слабо
связанные распределенные вычислительные сетки или решетки. Такие системы только
начинают развиваться, но их потенциал весьма высок.
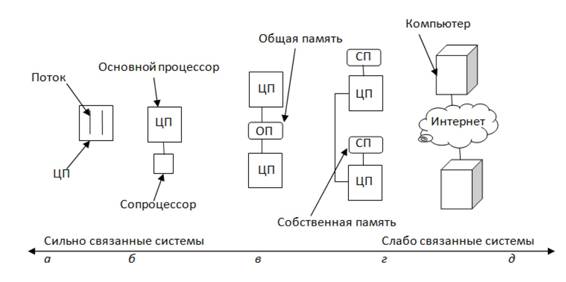
Связанность
процессоров
Вводится понятие связанность
процессоров:
1.Когда два процессора или обрабатывающих элемента
находятся рядом иобмениваются
большими объемами данных с небольшими задержками, они называются сильно
связанными (tightly coupled).
2.Когда два процессора или обрабатывающих элемента
располагаются далеко друг от друга и обмениваются небольшими объемами данных с
большими задержками, они называются слабо связанными (loosely coupled)
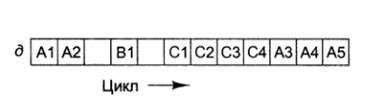
Рисунок 1 - Внутрипроцессорный параллелизм (а); сопроцессор (б); мультипроцессор
(в); мультикомпьютер (г); слабо связанная распределенная вычислительная система
(д)
Для всех современных конвейеризованных процессоров
характерна одна и та же проблема — если при запросе к памяти слово не
обнаруживается в кэшах первого и второго уровней, на загрузку этого слова в кэш
уходит длительное время, в течение которого конвейер простаивает.
Для решения этой проблемы предлагаются различные варианты
реализации многопоточности:
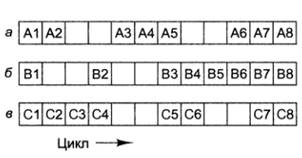
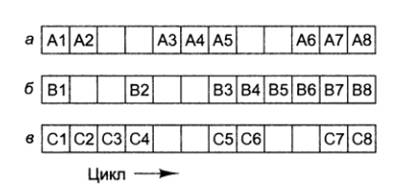
Общее правило работы мелкомодульной многопоточности
формулируется так: если в конвейере k ступеней, но по кругу можно запустить, по
меньшей мере, k программных потоков, то в одном потоке в любой отдельно взятый
момент не может выполняться более одной команды, поэтому конфликты между ними
исключены
В такой ситуации процессор может работать на полной
скорости, без простоя.
Вне зависимости от используемого варианта многопоточности,
необходимо как-то отслеживать принадлежность каждой операции к тому или иному
программному потоку. В рамках мелкомодульной многопоточности каждой операции
присваивается идентификатор потока, поэтому при перемещениях по конвейеру ее
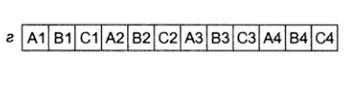
принадлежность не вызывает сомнений. Крупномодульная многопоточность
предусматривает возможность очистки конвейера перед запуском каждого
последующего потока. В таком случае четко определяется идентичность потока,
исполняемого в данный момент.
Данная методика эффективна только в том случае, если паузы
между переключениями значительно больше времени, необходимого для очистки
конвейера.
Мультипроцессоры и мультикомпьютеры
В любой параллельной компьютерной системе процессоры,
выполняющие разные части единого задания, должны как-то взаимодействовать друг с
другом, чтобы обмениваться информацией. Для обмена информацией предложено и
реализовано две стратегии: мультипроцессоры и мультикомпьютеры. Ключевое
различие между стратегиями состоит в наличии или отсутствии общей памяти. Это
различие сказывается как на конструкции, устройстве и программировании таких
систем, так и на их стоимости и размерах.
Мультипроцессоры
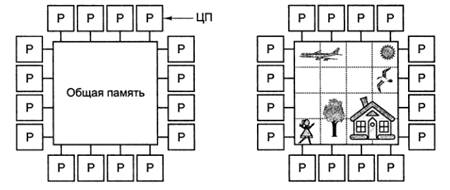
Параллельный компьютер, в котором все процессоры совместно
используют общую физическую память, называется мультипроцессором, или системой с
общей памятью.
Два процесса имеют возможность легко обмениваться
информацией — для этого один из них просто записывает данные в общую память, а
другой их считывает.
Все процессоры в мультипроцессоре используют единое
адресное пространство
®
функционирует только одна копия операционной системы.
Организация, в основе которой лежит единая система, и
отличает мультипроцессор от мультикомпьютера.
В одних мультипроцессорных системах только определенные
процессоры получают доступ к устройствам ввода-вывода, в других - каждый
процессор может получить доступ к любому устройству ввода-вывода.
Если все процессоры имеют равный доступ ко всем модулям
памяти и всем устройствам ввода-вывода, и между процессорами возможна полная
взаимозаменяемость, такой мультипроцессор называется симметричным (Symmetric
Multiprocessor, SMP).
При наличии большого числа быстродействующих процессоров,
которые постоянно пытаются получить доступ к памяти через одну и ту же шину,
будут возникать конфликты. Чтобы разрешить эту проблему и повысить
производительность компьютера, разработаны различные схемы. Один из вариантов
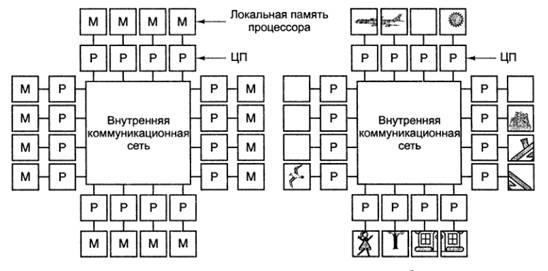
решения данной проблемы - это чтобы каждый процессор имел
собственную локальную память, недоступную для других процессоров. Эта память
используется для тех программ и данных, которые не нужно разделять между
несколькими процессорами. При доступе к локальной памяти основная шина не
используется, и, таким образом, объем передаваемой по ней информации становится
меньше.
Мультикомпьютеры
Во втором варианте параллельной архитектуры каждый
процессор имеет собственную память, доступную только этому процессору
Такая схема называется мультикомпьютером, или системой с
распределенной памятью
Каждый процессор в мультикомпьютере имеет собственную
локальную память, к которой этот процессор может обращаться, но никакой другой
процессор не может получить доступ к локальной памяти данного процессора
Мультипроцессоры имеют одно физическое адресное
пространство, разделяемое всеми процессорами, а мультикомпьютеры содержат
отдельные физические адресные пространства для каждого процессора
Поскольку процессоры в мультикомпьютере не могут
взаимодействовать друг с другом простыми обращениями к общей памяти, процессоры
обмениваются сообщениями через связывающую их коммуникационную сеть. ПО
мультикомпьютера имеет более сложную структуру, чем ПО мультипроцессора.
Примеры мультикомпьютеров - IBM BlueGene/L, Red Storm,
кластер Google.
Семантика памяти
Семантику памяти можно рассматривать как контракт между
программным и аппаратным обеспечением памяти. Если программное обеспечение
соглашается следовать определенным правилам, то память соглашается выдавать
определенные результаты.
Основная проблема -
сами правила, которые называются моделями состоятельности.
Строгая
состоятельность:
-При любом считывании из адреса х всегда
возвращается значение самой последней записи в х.
-Должен быть единственный модуль памяти, просто
обслуживающий все запросы по мере их поступления (первым поступил — первым
обработан), кэширование и дублирование данных не допускаются.
-Значительное торможение работы памяти.
Секвенциальная
состоятельность
-В соответствии с этой моделью при наличии
нескольких запросов на чтение и запись порядок обработки запросов определяется
аппаратно, но при этом все процессоры воспринимают один и тот же порядок.
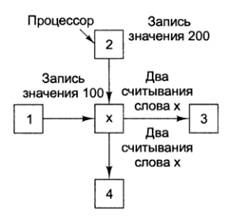
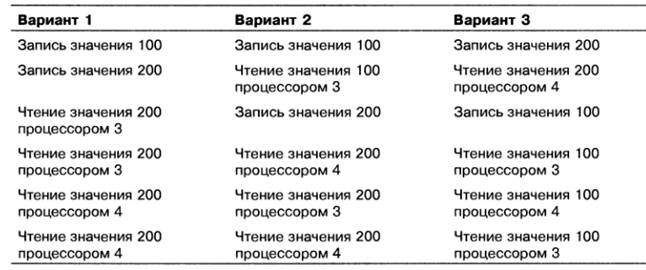
Пример.
Предположим, процессор 1 записывает значение 100 в слово х,
а через 1 нс процессор 2 записывает туда же значение 200. А теперь предположим,
что через 1 нс после начала второй операции записи (процесс записи еще не
закончен) два других процессора, 3 и 4, считывают слово х по два раза.
Два процессора записывают, а другие два процессора
считывают одно и то же слово из общей памяти
Возможные варианты очередности событий:
1.В первом варианте оба процессора получают значение 200 в
каждой из двух операций считывания.
2.Во втором варианте процессор 3 получает значения 100 и
200, а процессор 4 — оба раза но 200.
3.В третьем варианте процессор 3 получает два раза по 100,
а процессор 4 — значения 200 и 100.
Правила секвенциальной состоятельности не выглядят столь
«жестокими», как правила строгой состоятельности. Даже если несколько событий
совершаются одновременно, считается, что на самом деле они происходят в
определенном порядке (который может выбираться произвольно), и все процессоры
воспринимают именно этот порядок.
Процессорная
состоятельность
Не слишком строгая модель, но зато ее легче реализовать на
больших мультипроцессорах.
Свойства:
1.Все процессоры видят операции записи любого процессора в
том порядке, в котором эти операции выполняются
2.Все процессоры видят все операции записи в любое слово
памяти в одном и том же порядке
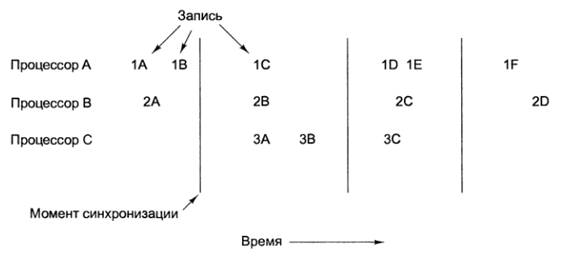
Пример: Два
процессора (1 и 2) начинают три операции записи значений 1А, 1В, 1Си 2А, 2В, 2С одновременно
Другие процессоры,
которые заняты считыванием слов из памяти, увидят какую-либо последовательность
из шести операций записи, например, 1А, 1В, 2А, 2В, 1С, 2С или 2А, 1А, 2В, 2С,
1В, 1С; и т. п.
При процессорной состоятельности не гарантируется, что
каждый процессор видит один и тот же порядок (в отличие от секвенциальной
состоятельности). Гарантируется абсолютно точно — ни один процессор не увидит
последовательность, в которой сначала выполняется операция 1В, а затем — 1А.
Порядок, в котором выполняются обращения одного и того же процессора, остается
одинаковым для всех наблюдателей.
Слабая
состоятельность
В модели слабой состоятельности не гарантируется, что
операции записи, произведенные одним процессором, будут восприниматься другими в
том же порядке. Один процессор может увидеть сначала операцию 1А, а потом 1В,
другой — сначала 1В, потом 1А
В слабо состоятельной памяти периодически выполняются
операции синхронизации, и процессоры разделяют порядок операций только по этим
периодам синхронизации.
Свободная
состоятельность
Используется нечто похожее на критические секции программы
- если процесс выходит за пределы критической области, это не значит, что все
записи должны немедленно завершиться. Требуется только, чтобы все записи были
завершены до того, как какой-нибудь процесс снова войдет в эту критическую
область. Операция синхронизации разделяется на две разные операции: acquire и
release.
Чтобы считать или записать совместно используемую
переменную, процессор (то есть его программное обеспечение) сначала должен
выполнить операцию acquire с переменной синхронизации, что позволит ему получить
монопольный доступ к общим данным. Далее процессор может делать с этими данными
все, что ему требуется (считывать или записывать), а по завершении он должен
выполнить операцию release с переменной синхронизации, чтобы показать, что он
завершил работу. Операция release не требует завершения незаконченных записей,
но сама она не может завершиться, пока не закончатся все ранее начатые операции
записи. Более того, новые операции с памятью могут начинаться сразу же. Когда
начинается следующая операция acquire, производится проверка, все ли предыдущие
операции release завершены.Если
нет, то операция acquire задерживается до тех пор, пока это не будет сделано (а
перед тем, как завершатся все операции release, должны быть завершены все
операции записи). Если следующая операция acquire выполняется через достаточно
длительный промежуток времени после последней операции release, ей не нужно
ждать, и она может войти в критическую область без задержки. Если операция
acquire выполняется через небольшой промежуток времени после операции release,
она (и все команды, которые должны выполняться следом) ожидает завершения всех
операций release.
Это гарантирует, что все переменные в критической области
будут обновлены.